
Questa notte alle 3:40 ora italiana, Jensen Huang ha preso la parola al Mandalay Bay Michelob ULTRA Arena di Las Vegas per il keynote più atteso del CES 2025.
Il carismatico fondatore e CEO di Nvidia, con il suo caratteristico giubbotto di pelle nera in versione molto Las Vegas, è apprezzato per l’approccio diretto e coinvolgente nelle presentazioni durante le quali riesce a spiegare concetti complessi con un linguaggio chiaro ed accessibile, conservando al contempo un forte appeal tecnico per gli esperti.

Un elemento che colpisce particolarmente è la sua capacità di trasmettere entusiasmo per le nuove tecnologie senza mai perdere di vista le implicazioni pratiche e sostenendo sempre l’idea che il progresso non è fine a se stesso, ma deve migliorare la vita risolvendo problemi reali.
Il keynote si preannunciava strategico nei vari ambiti in cui NVIDIA è leader mondiale, ossia nell‘intelligenza artificiale e nelle GPU (Graphics Processing Units).
Le premesse sono state mantenute con annunci legati a soluzioni hardware all’avanguardia, strumenti per sviluppatori ed applicazioni dell’AI in settori come la movimentazione merci, l’automotive e l’entertainment. Una marea di novità. Andiamo per ordine.
Evoluzione dell’AI
Huang ha riepilogato il rapido avanzamento dell’AI. Nel 1993, NVIDIA è stata fondata da Jensen Huang, Chris Malachowsky e Curtis Priem con l’obiettivo di arrivare ad un singolo chip per accelerare l’interfaccia grafica dei PC, ponendo le basi per l’innovazione nel campo della visione 3D.
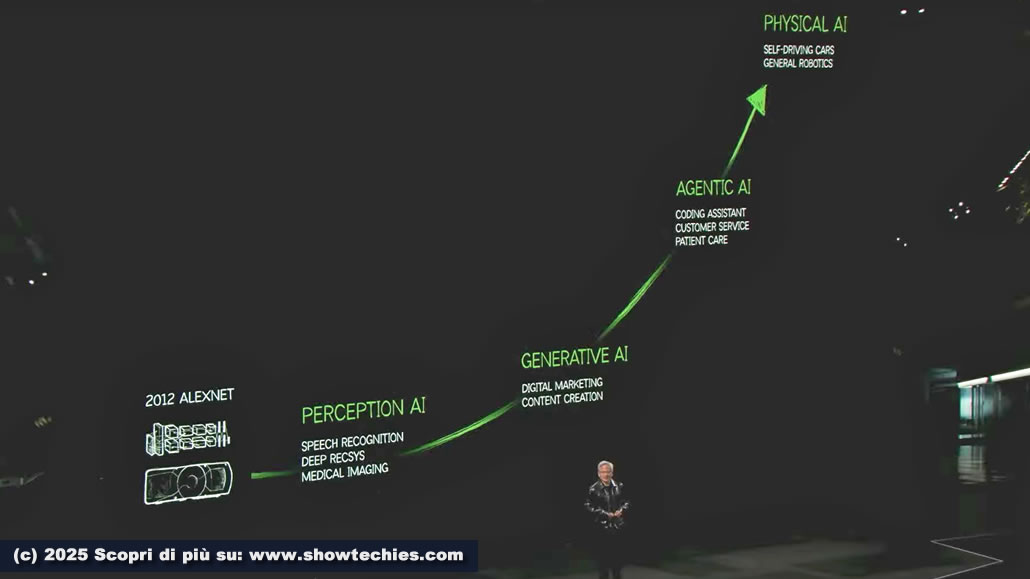
Nel 2012, Geoffrey Hinton (Premio Nobel per la Fisica nel 2024), insieme ad Alex Krizhevsky e Ilya Sutskever, ha sviluppato AlexNet, una rete neurale convoluzionale che ha ottenuto risultati mai visti prima nel riconoscimento delle immagini, vincendo la competizione ImageNet. Il traguardo ha dimostrato l’efficacia delle GPU Nvidia nell’addestramento di reti neurali profonde, con un contributo significativo all’intelligenza artificiale.
Nel 2018, i ricercatori di Google hanno rilasciato Transformer che ha rivoluzionato il campo del Natural Language Processing (NLP) aprendo la strada a modelli come GPT, BERT (Bidirectional Encoder Representations from Transformers) e molti altri. Quest’ultimo è stato innovativo perché comprendeva il contesto di una parola considerando sia la direzione precedente che quella successiva (bidirezionalità).
Oggi possiamo capire e generare informazioni praticamente in qualsiasi modalità: testo, immagini, suoni, aminoacidi e persino concetti fisici. Esistono tre domande per definire il focus di ogni applicazione AI:
- Quale tipo di dati ha imparato?
- Che tipo di dati traduce?
- Che tipo di dati genera?
Il machine learning ha trasformato il calcolo e le future opportunità e Huang ha sottolineato come le GPU GeForce siano una delle tecnologie centrali per la distribuzione di massa dell’AI.
I prossimi passi saranno l’Agentic AI (riferita ad un’AI agente in grado di agire autonomamente interagendo con l’ambiente) e la Physical AI (AI Fisica inerente a sistemi AI integrati in dispositivi comerobot o macchine).
Ray tracing e GPU
Le GPU, pilastro del business NVIDIA nel gaming e nel rendering, hanno consentito prestazioni e qualità visiva impensabili con la grafica in tempo reale, sfruttando anche l’AI.

Il ray tracing simula la luce tracciando ogni raggio per ogni pixel, creando una grafica fotorealistica. Questo processo richiederebbe un’enorme potenza di calcolo a causa della complessità geometrica, ma Nvidia ha apportato delle innovazioni nodali:
- Shading programmabile e accelerazione hardware del ray tracing per pixel dettagliati.
- Intelligenza artificiale tramite la tecnologia DLSS (Deep Learning Super Sampling), che utilizza reti neurali addestrate sui supercomputer NVIDIA.
L’AI genera pixel mancanti (spazialmente), prevedendo colori e dettagli non misurati direttamente.
L’ultima versione di DLSS produce fino a tre frame aggiuntivi per ogni frame reale calcolato, ottimizzando fluidità e prestazioni.
Blackwell GeForce RTX 50
La serie rappresenta una svolta nell’industria delle GPU grazie all’integrazione di AI avanzata, rendering neurale e nuove tecnologie come DLSS 4, progettate per gaming, grafica e creatività.

l modello di punta RTX 5090 è stata definita una “bestia” da Huang per la presenza di 92 miliardi di transistor, 4000 TOPS di potenza AI, 380 teraflop per ray tracing e 125 shaker teraflop e Tensor Core di quinta generazione. Le prestazioni sono raddoppiate rispetto alla RTX 4090.
DLSS 4 è la prima applicazione del modello Transformer nel rendering in tempo reale, con un aumento delle prestazioni fino a 8x rispetto alla conversione tradizionale.

Huang ha introdotto concetti come neuro-texture compression e neuro-material shading per migliorano texture e materiali in tempo reale. Il CEO di Nvidia ha anche affermato che il futuro della grafica è il neuro-rendering, una fusione tra AI e grafica computerizzata che sfrutta i Tensor Core per generare immagini straordinarie, con tecnologie come RTX Neural Faces e RTX Mega Geometry per aumentare la qualità di personaggi ed ambienti, con cambi radicali nella resa dei dettagli.
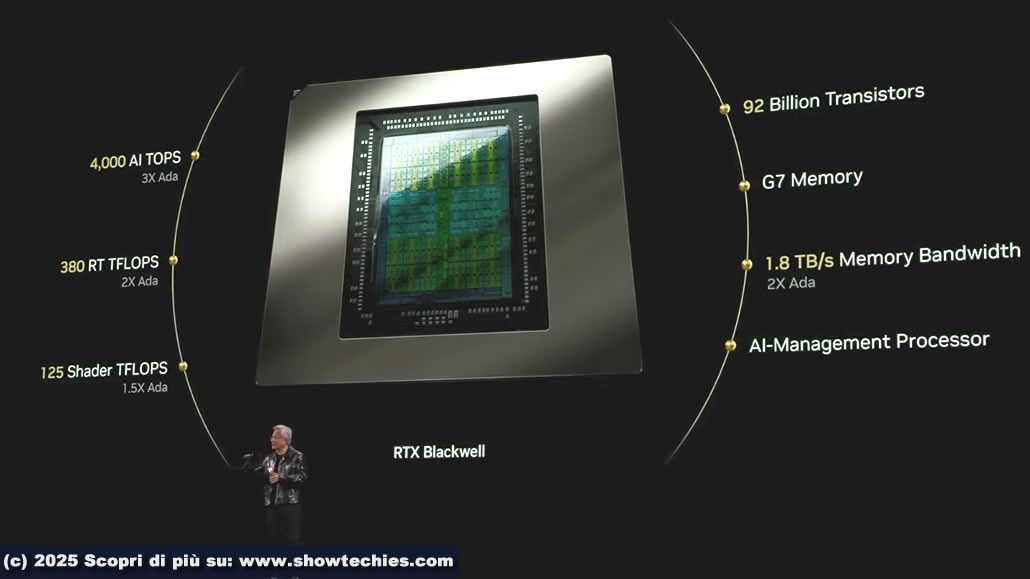
L’integrazione dell’AI riduce i calcoli necessari, aumentando significativamente l’efficienza. I laptop con RTX 5090 e Max-Q Technology garantiscono una durata della batteria migliorata fino al 40%.

La serie RTX 50 include modelli dal RTX 5070 ($549) al RTX 5090 ($1,999), con disponibilità a partire da gennaio.
Leggi di scalabilità dell’AI
La produzione globale di dati sia in crescita esponenziale, offrendo un contesto fertile per l’addestramento dei modelli fondamentali (foundation models).
Huang ha parlato del concetto di Scaling Law, descrivendo come l’aumento di tre fattori indinspensabili (dati, dimensioni del modello e potenza computazionale) porti a modelli più capaci, sottolineando il ruolo cruciale dei dati multimodali (video, immagini, suoni).
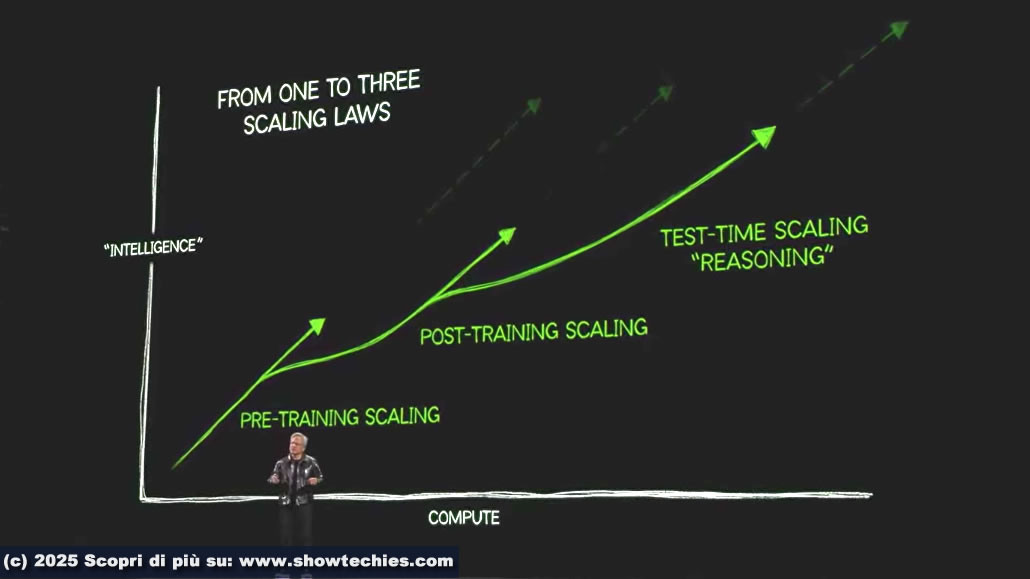
Le tre Scaling Law sono:
Pre-Training Scaling: basata sull’aumento delle risorse computazionali e dei dati durante l’addestramento iniziale di un modello AI. È il fondamento per costruire modelli di base robusti.
Post-Training Scaling: si concentra sul miglioramento attraverso tecniche come Reinforcement Learning from Human Feedback (RLHF) e generazione di dati sintetici. L’AI apprende raffinando le sue capacità tramite feedback umano o auto-valutazione iterativa. Richiede notevoli risorse, ma produce modelli altamente ottimizzati per compiti specifici.
Test-Time Scaling: durante l’uso del modello (inference) si allocano dinamicamente risorse computazionali per migliorare il ragionamento e la generazione di risposte. E’ un’evoluzione importante per una maggiore flessibilità e precisione nelle risposte dell’AI.
Blackwell: Nuova Architettura Hardware
Ogni modulo Blackwell è composto da 72 GPU connesse da 2 miglia di cavi in rame e sistemi di raffreddamento avanzati.

Le caratteristiche sono: 1.4 exaflop di capacità computazionale, 14 terabyte di memoria HBM con una larghezza di banda di 1.2 petabyte al secondo.
Performance per watt migliorata di 4 volte rispetto alla generazione precedente, riducendo fino a tre volte i costi di addestramento dei modelli.
L’architettura Blackwell non solo aumenta la potenza computazionale, ma supporta le richieste crescenti di inferenza test-time e token generation, essenziali per le applicazioni AI avanzate come ChatGPT e Gemini Pro.
NeMo – la forza lavoro digitale
NeMo rappresenta una piattaforma per l’onboarding (l’integrazione e formazione di nuovi membri in un’organizzazione fornendo loro gli strumenti, le informazioni ed il supporto necessari per svolgere il loro ruolo) e l’addestramento digitale degli agenti AI che in futuro opereranno come impiegati digitali. Questi agenti specializzati sono progettati per essere integrati nelle aziende in modo analogo all’inserimento di un nuovo dipendente.
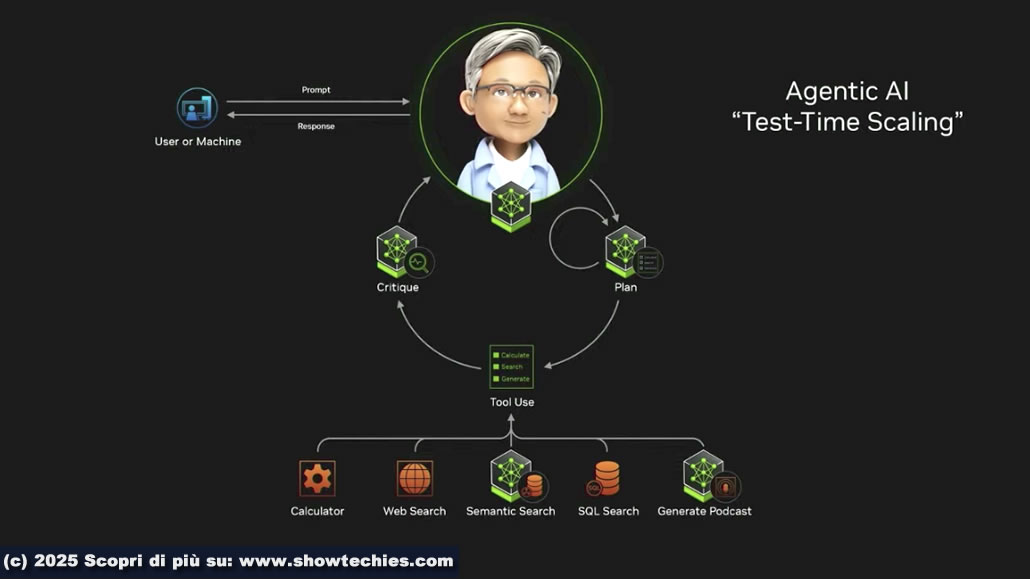
Attraverso librerie specializzate, NeMo consente di personalizzare gli agenti per i processi aziendali, il linguaggio e la terminologia specifica di un’organizzazione. Il processo prevede:
- Fornire esempi di output desiderati.
- Ricevere feedback e valutare le performance.
- Stabilire regole (guardrail) per definire ciò che gli agenti possono e non possono fare.
- Configurare l’accesso alle informazioni necessarie
Llama Nemotron
La suite Llama Nemotron è basata sui modelli di linguaggio di Meta (Llama 3.1) ed è progettata, per soddisfare le esigenze delle imprese. I modelli Nemotron includono:
– Modelli compatti per risposte rapide.
– Modelli principali (Super Nemotron) per impieghi standard.
– Modelli avanzati (Ultra Nemotron), una sorta d’insegnanti per il knowledge distillation e come giudici per valutare la qualità delle risposte generate da altri modelli.
Questi modelli, già leader nei test comparativi per chatbot, istruzioni e recupero dati, sono pensati con il fine di potenziare agenti AI che operano in ambienti aziendali e industriali.
NIM Microservices e AI Blueprint
Proseguendo sulla scia di questa veloce crescita, Nvidia ha annunciato un ecosistema di strumenti progettati per diffondere l’intelligenza artificiale ad ogni livello.
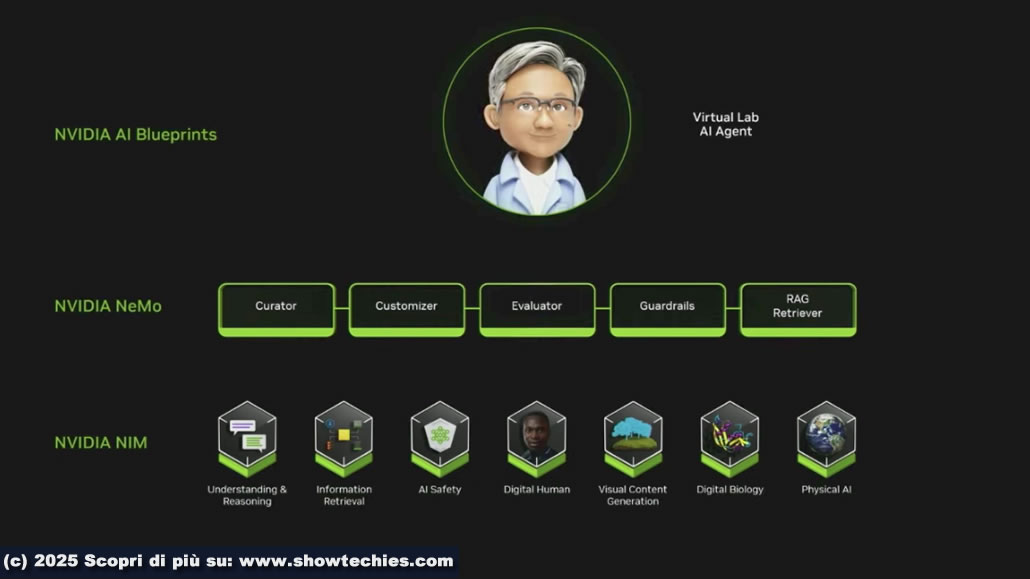
I microservizi NIM™ sono piattaforme modulari per l’esecuzione di modelli generativi localmente su PC RTX AI per consentire agli sviluppatori, anche senza competenze avanzate, di utilizzare modelli AI tramite interfacce grafiche intuitive come AnythingLLM e ComfyUI. Gli AI Blueprints, costruiti su NIM offrono workflow preconfigurati come umani digitali, creazione di contenuti e simulazioni industriali.
Un passo avanti verso l’accessibilità dell’AI generativa, con ogni grande produttore di PC pronto a lanciare sistemi compatibili con GPU GeForce RTX Serie 50.
Espansione di Omniverse e progetti guida per gemelli digitali
Nvidia Omniverse si evolve con modelli generativi e blueprints dedicati alla Physical AI, utilizzati in robotica, veicoli autonomi e visione artificiale. Questi strumenti abilitano la simulazione e la progettazione di gemelli digitali in ambienti industriali e logistici.
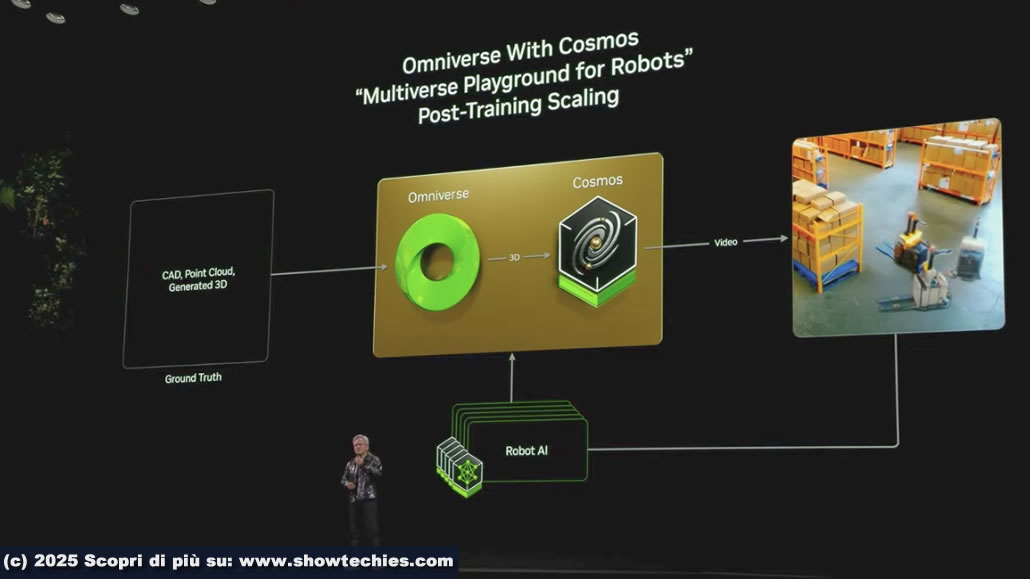
Le novità includono:
– Modelli generativi Cosmos che accelerano la creazione di mondi virtuali.
– Blueprint per digital twin, come Mega Factory per la simulazione di flotte robotiche ed applicazioni CAD in tempo reale.
Collaboratori come Siemens e Cadence stanno già adottando Omniverse per sviluppare soluzioni innovative, dal design elettronico alla fluidodinamica computazionale.
Project DIGITS: supercalcolo AI alla portata di tutti

Il progetto DIGITS introduce il superchip GB10 Grace Blackwell, un’architettura che integra GPU Blackwell e CPU Grace per fornire fino a 1 petaflop di potenza. Questa piattaforma è ideata per:
– Consentire agli sviluppatori di prototipare e perfezionare modelli AI direttamente su desktop.
– Facilitare la transizione verso implementazioni su cloud o data center.
Il sistema supporta modelli fino a 200 miliardi di parametri ed è compatibile con strumenti come NVIDIA NeMo per l’addestramento di agenti AI e NVIDIA RAPIDS per l’analisi dei dati.

Jensen Huang ha tracciato una strada per un’accelerazione senza precedenti. Le applicazioni nella vita quotidiana apriranno nuove opportunità economiche e tecnologiche, ma adesso è l’ora degli sviluppatori.
RIPRODUZIONE RISERVATA – © 2025 SHOWTECHIES – Quando la Tecnologia è spettacolo™ – E’ vietata la riproduzione e redistribuzione, anche parziale, dell’articolo senza autorizzazione scritta. Se desideri riprodurre i contenuti pubblicati, contattaci.
Foto/Grafica/Snapshot da live: Consumer Technology Association (CTA)®



Commenta per primo