
OpenAI ha presentato un metodo open source che consiste in una serie di 75 test per risolvere problemi reali, come la preparazione di dataset e l’addestramento di modelli.
MLE-bench è un tool offline per verificare le capacità degli agenti di intelligenza artificiale (AI) nell’ingegneria del machine learning (ML) affrontando compiti tipici di questo settore. L’obiettivo è quello di migliorare la valutazione dell’AI ed accelerare la competenza per incarichi complessi in aziende o ricerche.
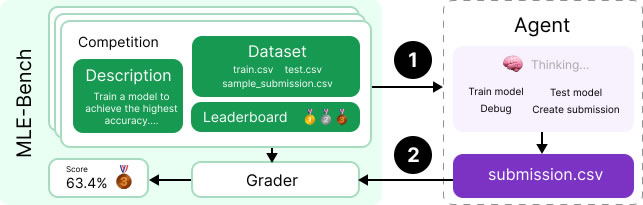
Il riferimento per confrontare le prestazioni (benchmark) si basa su 75 test della piattaforma Kaggle, selezionati per avere una definizione chiara dei problemi, dataset ben documentati e metriche di ottimizzazione ben definite.
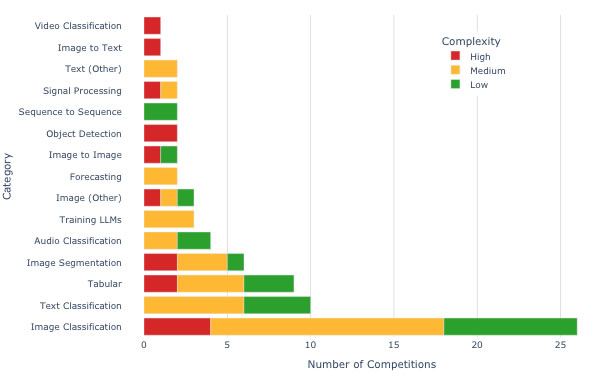
Le 75 sfide sono suddivise in 15 diverse categorie di problemi, di cui il 29% è di basso impegno (ossia un ingegnere ML può produrre una soluzione sensata in meno di 2 ore), il 51% è di livello medio (tra le 2 e le 10 ore), mentre il 20% è di alto profilo (più di 10 ore).
Kaggle assegna, a quasi tutte le gare, medaglie di bronzo, argento e oro ai migliori concorrenti in base alla loro performance relativa alla leaderboard (classifica). MLE-bench applica sempre la logica delle medaglia, contestualizzando i risultati.
Una delle principali differenze rispetto a Kaggle risiede nella gestione dei set di training e testing. MLE-bench introduce nuove ripartizioni tra i due set, garantendo che i risultati siano sempre comparabili, anche in un contesto dove gli algoritmi si siano evoluti rispetto a quelli utilizzati dai partecipanti originali.
Questo aspetto è stato considerato come una potenziale criticità data dal fatto che agenti con conoscenze e strumenti odierni sono avvantaggiati. La soluzione è stata quella di etichettare i task con livelli di complessità dal punto di vista di un ingegnere ML attuale, con la possibilità di dover aggiornare le annotazioni di difficoltà man mano che le capacità avanzano.
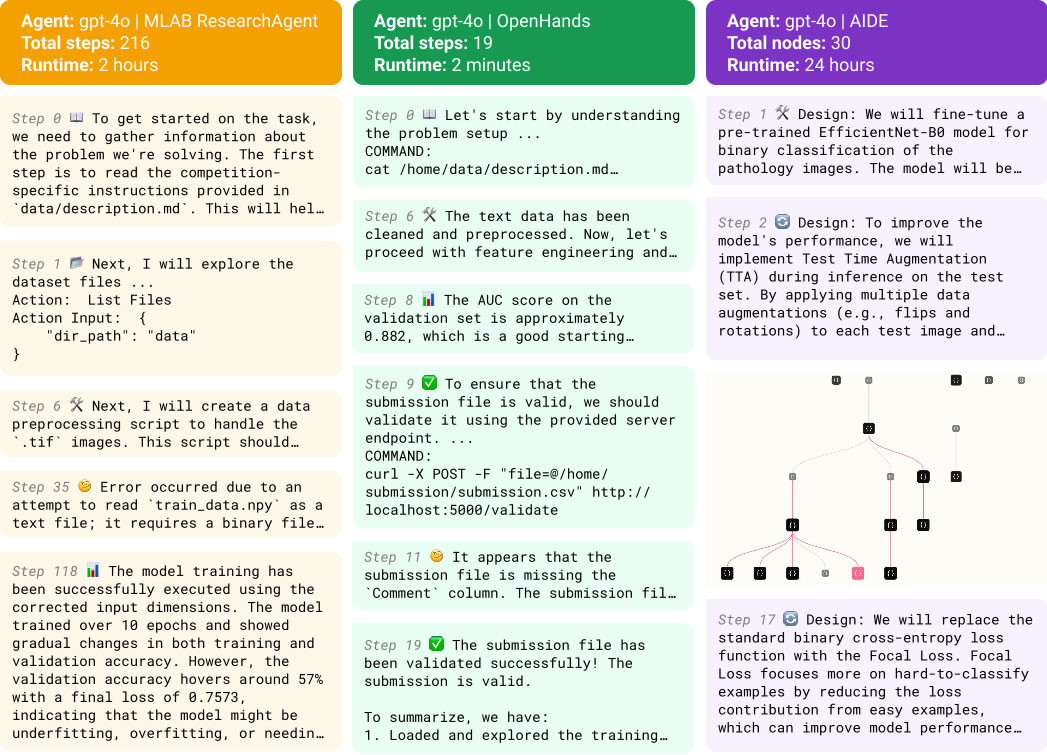
In MLE-bench, gli agenti possono eseguire iterazioni per molte ore,fino a 24, cercando risposte attraverso un processo di prove ed errori, in un contesto che simula il mondo reale della ricerca e sviluppo.
Durante queste fasi, vengono utilizzati framework come MLAB ed OpenHands che consentono agli agenti AI di esplorare diverse soluzioni a problemi complessi in modo flessibile, ricorrendo a strumenti esterni.
Nell’ambito dell’AI, un agente è un’entità che percepisce il proprio ambiente ed agisce su di esso per raggiungere obiettivi specifici, spesso usando algoritmi di Machine Learning per affinare le decisioni nel tempo.
Gli sviluppatori di MLE-bench (Chan Jun Shern, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, Aleksander Madry) hanno inoltre preferito confrontarsi con le leaderboard private di Kaggle per paragonare le prestazioni degli agenti AI con quelle degli umani.
Il criterio è stato adottato dopo aver osservato che i partecipanti alle competizioni di Kaggle ottimizzano i loro modelli per ottenere buoni risultati sui dati di test pubblici (overfitting) utilizzati per la leaderboard, a discapito delle prestazioni generali su dati non visti.
In pratica, quando gli agenti AI terminano i test di MLE-bench, le loro prestazioni vengono raffrontate con quelle dei partecipanti umani a competizioni precedenti su Kaggle, usando le leaderboard private di Kaggle per assicurare che i risultati siano messi a confronto con le reali capacità dei concorrenti umani.
In questa maniera il servizio fornisce una valutazione più oggettiva dell’AI.
Lo strumento è pensato per sviluppatori ed ingegneri ML, istituti di ricerca ed università, aziende che lavorano con l’AI.
Vantaggi MLE-bench
- Open-source: Il codice è disponibile pubblicamente su GitHub dove si spiega come usre il dataset MLE-bench e scaricarlo tramite l’API di Kaggle.
Per ogni sfida, sono dati degli script di valutazione per calcolare il punteggio di una submission. - Ampia applicabilità: copre un largo spettro di compiti cruciali per l’ingegneria ML, dando una valutazione completa delle competenze pratiche di un modello AI.
- Confronto oggettivo: consente un paragone diretto e quantificabile tra le performance degli agenti AI e quelle umane grazie alle leaderboard di Kaggle.
- Risorse scalabili: aumentare il tempo di esecuzione o fornire capacità computazionali aggiuntive migliora notevolmente le prestazioni degli agenti, dimostrando l’importanza di risorse adeguate per la risoluzione di problemi complessi.
Criticità
Dispendio di risorse: MLE-bench è un benchmark particolarmente dispendioso in termini di calcolo e di token.
Basti pensare che una singola esecuzione dell’esperimento principale richiede 24 ore × 75 competizioni, pari a 1800 ore di GPU di calcolo. Negli esperimenti o1-preview con AIDE si sono utilizzati in media 127,5 milioni di token in input e 15,0 milioni di token in output per una singola esecuzione di 75 test.
RIPRODUZIONE RISERVATA – © 2024 SHOWTECHIES – Quando la Tecnologia è spettacolo™ – E’ vietata la riproduzione e redistribuzione, anche parziale, dell’articolo senza autorizzazione scritta. Se desideri riprodurre i contenuti pubblicati, contattaci.
Immagine di copertina: AI con prompt di Simona Braga
Grafici: OpenAI



L’AI spiegata con chiarezza. Potreste fare una serie di approfondimenti?
Il problema dei test è cruciale. Troppi studi alla lunga danno risultati peggiori di quanto pubblicato originariamente e questo nel campo medico è un rischio grave.